C++遍历中文字符串指南:UTF-8编码解析 #
在C++开发中,正确处理中文字符串是一个常见挑战。本文将深入探讨UTF-8编码原理,通过实例讲解如何正确遍历中文字符串,避免常见的乱码问题。
和大家分享下如何遍历中文字符串,主要是如何打印中文字符,因为中文字符串每个字符占用不只一个字节的空间,如果我们逐个字节遍历,会出现奇怪的结果。而 UTF-8 编码写的中文字符是有特定结构的,我们可以按照它的规则去遍历打印。
下面是详情:
前提:UTF-8 编码。
先看下面的代码和运行结果:
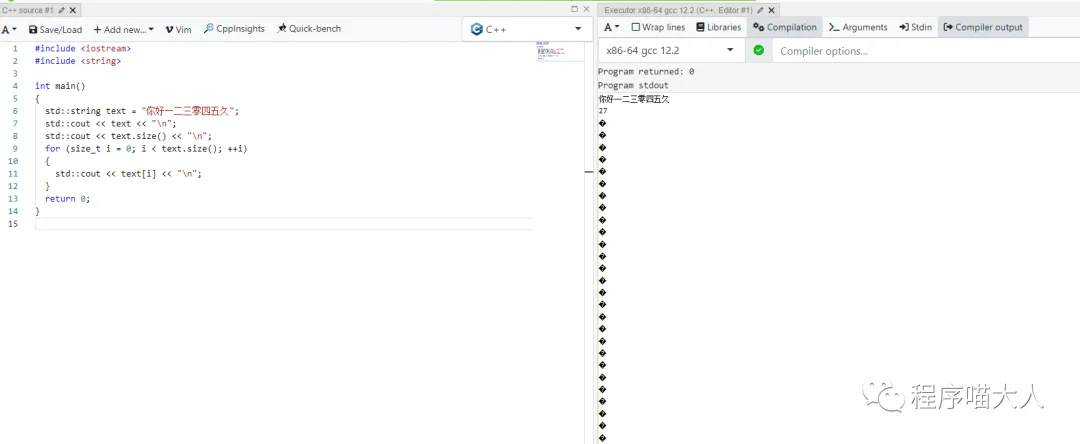
上面代码定义了一个 9 个中文的字符串,但打印 size 确是 27,挨个字符遍历也都是。
这个本质是因为中文不只占用一个字节的空间,换一种方式遍历:
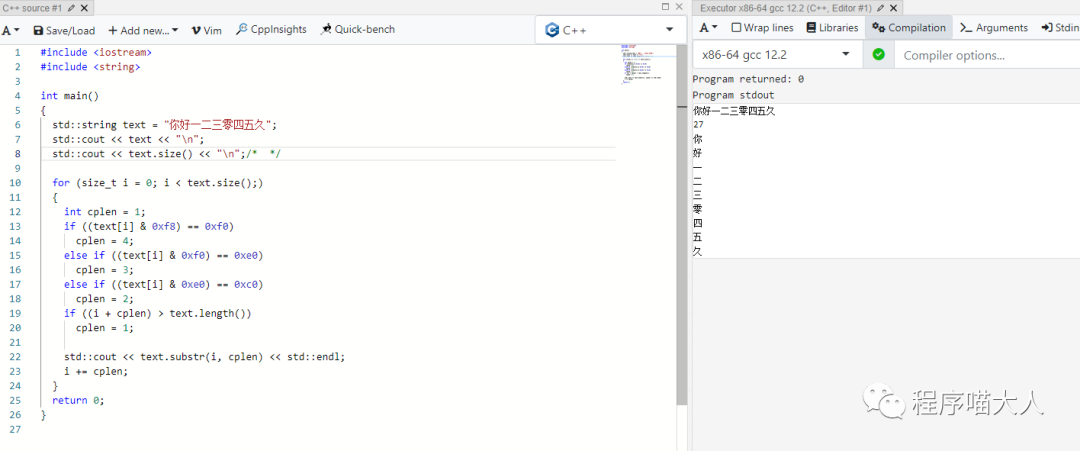
因为一个中文字符不一定占用几个字节,但它们的长度其实可以从字符的头中读取出来,这点可以查看 UTF-8 的 Wiki 介绍:https://en.wikipedia.org/wiki/UTF-8#Description
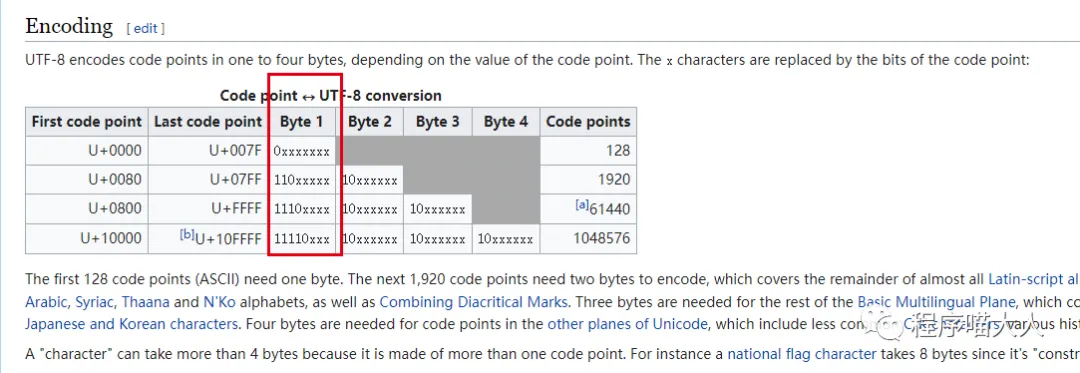
这里可以看到,通过 Byte1 的前 4 位就可以区分出这个字符究竟占用几个字节,所以就有了上述的遍历方式。
具体学习可以看这两个链接:
https://en.wikipedia.org/wiki/UTF-8#Description
https://stackoverflow.com/questions/40054732/c-iterate-utf-8-string-with-mixed-length-of-characters