C++拷贝构造函数为什么要用引用参数? #
训练营里有同学问:
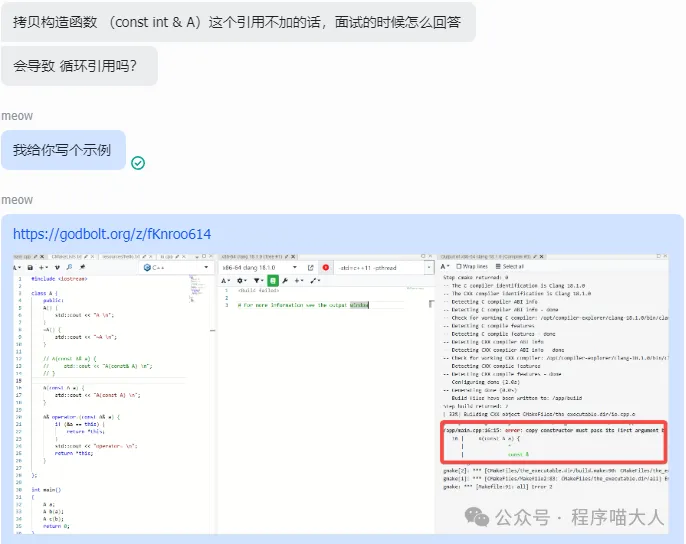
那拷贝构造函数不加引用会怎么样呢?
贴段代码:
#include <iostream>
class A {
public:
A() {
std::cout << "A \n";
}
~A() {
std::cout << "~A \n";
}
// A(const A& a) {
// std::cout << "A(const& A) \n";
// }
A(const A a) {
std::cout << "A(const A) \n";
}
A& operator=(const A& a) {
if (&a == this) {
return *this;
}
std::cout << "operator= \n";
return *this;
}
};
编译结果如图:

可以看到,如果拷贝构造函数不加引用,编译都会失败的,那为什么编译器要这样限制,为什么一定要加引用呢?
拷贝构造函数的参数必须是引用,因为如果不是,我们将不得不通过值传递对象。通过值传递对象将需要拷贝对象,这将调用拷贝构造函数。
这会导致拷贝构造函数调用的无限循环,而通过使用引用,就可以避免这个无限循环,因为引用不会创建新对象,而是指向现有对象的内存位置。
考虑以下带有接受引用参数的拷贝构造函数的类:
class MyClass {
public:
int a;
// 常规构造函数
MyClass(int value) : a(value) {}
// 接受引用参数的拷贝构造函数
MyClass(const MyClass &obj) {
a = obj.a;
}
};
int main() {
MyClass original(5); // 调用常规构造函数
MyClass copy(original); // 调用接受引用参数的拷贝构造函数
}
在这个例子中,创建 copy 对象时,调用了拷贝构造函数,并且它接受对 original 对象的引用。这避免了无限循环问题,因为引用简单地指向现有对象的内存位置,并且在过程中没有创建新对象。
如果不加引用:
MyClass(MyClass obj) {
a = obj.a;
}
这将在拷贝时导致无限循环,因为:
- 通过值传递时会创建一个新对象。
- 创建新对象需要调用拷贝构造函数
- 调用拷贝构造函数需要通过值传递对象,导致步骤1。
通过在拷贝构造函数中使用引用参数,可以防止这种无限循环,因为在传递引用时不会创建新对象。
所以编译器直接在源头就规避了这种问题,防止我们多踩坑。
总结 #
拷贝构造函数的参数必须是引用,因为如果不是,我们将不得不通过值传递对象。通过值传递对象将需要拷贝对象,这将调用拷贝构造函数。
这会导致拷贝构造函数调用的无限循环,而通过使用引用,就可以避免这个无限循环,因为引用不会创建新对象,而是指向现有对象的内存位置。